![]()
Authentic CKAD Dumps With 100% Passing Rate Practice Tests Dumps
Linux Foundation CKAD Real Exam Questions Guaranteed Updated Dump from Dumpexams
Linux Foundation CKAD exam is an excellent opportunity for developers to demonstrate their Kubernetes skills and gain recognition for their expertise. Whether you are a seasoned Kubernetes professional or just starting out, this certification can help you take your career to the next level and open up new opportunities in the rapidly evolving world of cloud-native development.
Linux Foundation CKAD certification exam is an excellent certification program for developers who work with Kubernetes. Linux Foundation Certified Kubernetes Application Developer Exam certification exam is designed to test the candidate's ability to deploy, manage and troubleshoot Kubernetes applications. Linux Foundation Certified Kubernetes Application Developer Exam certification exam is an online, proctored exam that can be taken from anywhere in the world. Linux Foundation Certified Kubernetes Application Developer Exam certification is ideal for developers who are looking to advance their careers in the field of cloud-native application development and for organizations who are looking to identify qualified professionals who can help them to build and manage Kubernetes applications.
NEW QUESTION # 18 
Context
A container within the poller pod is hard-coded to connect the nginxsvc service on port 90 . As this port changes to 5050 an additional container needs to be added to the poller pod which adapts the container to connect to this new port. This should be realized as an ambassador container within the pod.
Task
* Update the nginxsvc service to serve on port 5050.
* Add an HAproxy container named haproxy bound to port 90 to the poller pod and deploy the enhanced pod.
Use the image haproxy and inject the configuration located at /opt/KDMC00101/haproxy.cfg, with a ConfigMap named haproxy-config, mounted into the container so that haproxy.cfg is available at
/usr/local/etc/haproxy/haproxy.cfg. Ensure that you update the args of the poller container to connect to localhost instead of nginxsvc so that the connection is correctly proxied to the new service endpoint. You must not modify the port of the endpoint in poller's args . The spec file used to create the initial poller pod is available in /opt/KDMC00101/poller.yaml See the solution below.
Answer:
Explanation:
Explanation
Solution:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 90
This makes it accessible from any node in your cluster. Check the nodes the Pod is running on:
kubectl apply -f ./run-my-nginx.yaml
kubectl get pods -l run=my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-jr4a2 1/1 Running 0 13s 10.244.3.4 kubernetes-minion-905m my-nginx-3800858182-kna2y 1/1 Running 0 13s 10.244.2.5 kubernetes-minion-ljyd Check your pods' IPs:
kubectl get pods -l run=my-nginx -o yaml | grep podIP
podIP: 10.244.3.4
podIP: 10.244.2.5
NEW QUESTION # 19
Refer to Exhibit.
Task
A deployment is falling on the cluster due to an incorrect image being specified. Locate the deployment, and fix the problem.
Answer:
Explanation:
create deploy hello-deploy --image=nginx --dry-run=client -o yaml > hello-deploy.yaml Update deployment image to nginx:1.17.4: kubectl set image deploy/hello-deploy nginx=nginx:1.17.4
NEW QUESTION # 20
Context
Context
A user has reported an aopticauon is unteachable due to a failing livenessProbe .
Task
Perform the following tasks:
* Find the broken pod and store its name and namespace to /opt/KDOB00401/broken.txt in the format:
The output file has already been created
* Store the associated error events to a file /opt/KDOB00401/error.txt, The output file has already been created. You will need to use the -o wide output specifier with your command
* Fix the issue.
Answer:
Explanation:
Solution:
Create the Pod:
kubectl create -f http://k8s.io/docs/tasks/configure-pod-container/exec-liveness.yaml Within 30 seconds, view the Pod events:
kubectl describe pod liveness-exec
The output indicates that no liveness probes have failed yet:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "gcr.io/google_containers/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "gcr.io/google_containers/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e After 35 seconds, view the Pod events again:
kubectl describe pod liveness-exec
At the bottom of the output, there are messages indicating that the liveness probes have failed, and the containers have been killed and recreated.
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "gcr.io/google_containers/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "gcr.io/google_containers/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory Wait another 30 seconds, and verify that the Container has been restarted:
kubectl get pod liveness-exec
The output shows that RESTARTS has been incremented:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 m
NEW QUESTION # 21
Context
Context
A container within the poller pod is hard-coded to connect the nginxsvc service on port 90 . As this port changes to 5050 an additional container needs to be added to the poller pod which adapts the container to connect to this new port. This should be realized as an ambassador container within the pod.
Task
* Update the nginxsvc service to serve on port 5050.
* Add an HAproxy container named haproxy bound to port 90 to the poller pod and deploy the enhanced pod. Use the image haproxy and inject the configuration located at /opt/KDMC00101/haproxy.cfg, with a ConfigMap named haproxy-config, mounted into the container so that haproxy.cfg is available at /usr/local/etc/haproxy/haproxy.cfg. Ensure that you update the args of the poller container to connect to localhost instead of nginxsvc so that the connection is correctly proxied to the new service endpoint. You must not modify the port of the endpoint in poller's args . The spec file used to create the initial poller pod is available in /opt/KDMC00101/poller.yaml
Answer:
Explanation:
Solution:
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
run: my-nginx
replicas: 2
template:
metadata:
labels:
run: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
ports:
- containerPort: 90
This makes it accessible from any node in your cluster. Check the nodes the Pod is running on:
kubectl apply -f ./run-my-nginx.yaml
kubectl get pods -l run=my-nginx -o wide
NAME READY STATUS RESTARTS AGE IP NODE
my-nginx-3800858182-jr4a2 1/1 Running 0 13s 10.244.3.4 kubernetes-minion-905m my-nginx-3800858182-kna2y 1/1 Running 0 13s 10.244.2.5 kubernetes-minion-ljyd Check your pods' IPs:
kubectl get pods -l run=my-nginx -o yaml | grep podIP
podIP: 10.244.3.4
podIP: 10.244.2.5
NEW QUESTION # 22
Context
Anytime a team needs to run a container on Kubernetes they will need to define a pod within which to run the container.
Task
Please complete the following:
* Create a YAML formatted pod manifest
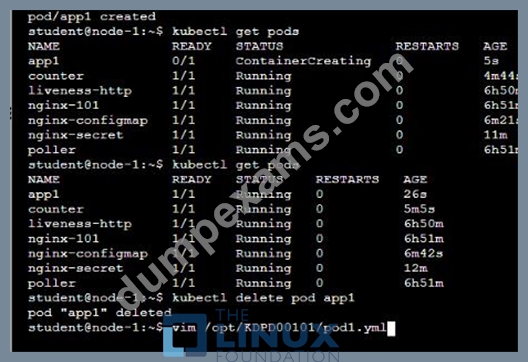
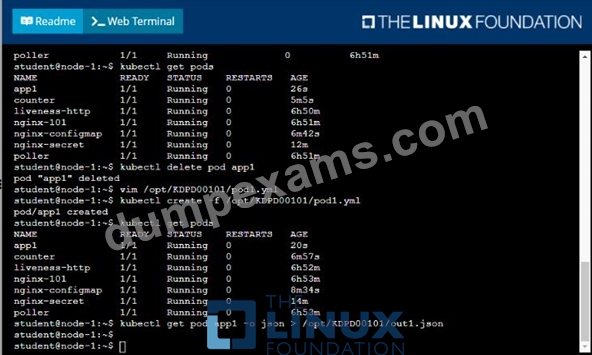
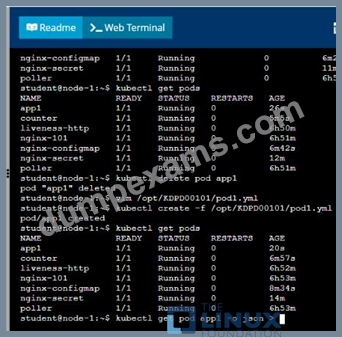
/opt/KDPD00101/podl.yml to create a pod named app1 that runs a container named app1cont using image Ifccncf/arg-output
with these command line arguments: -lines 56 -F
* Create the pod with the kubect1 command using the YAML file created in the previous step
* When the pod is running display summary data about the pod in JSON format using the kubect1 command and redirect the output to a file named /opt/KDPD00101/out1.json
* All of the files you need to work with have been created, empty, for your convenience
- A. Solution:

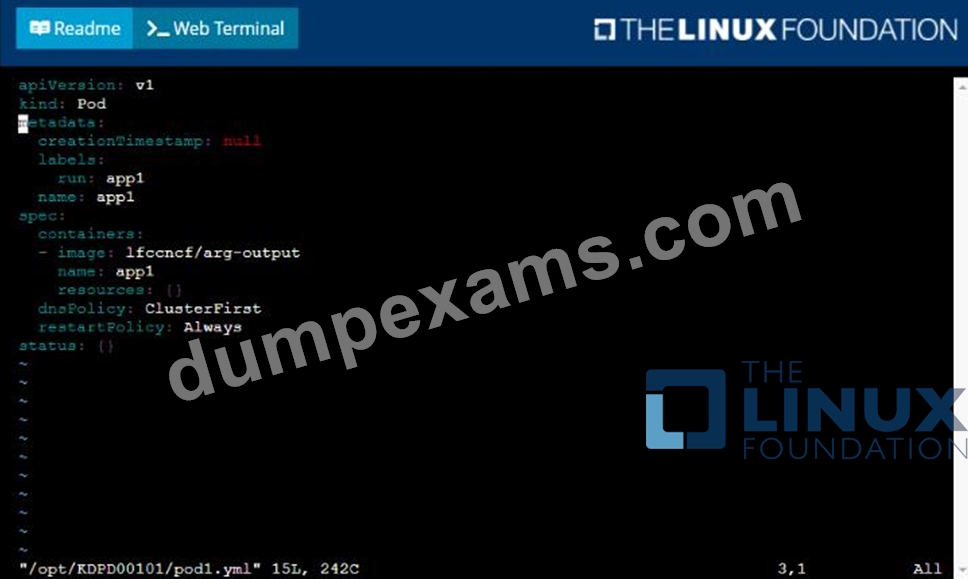
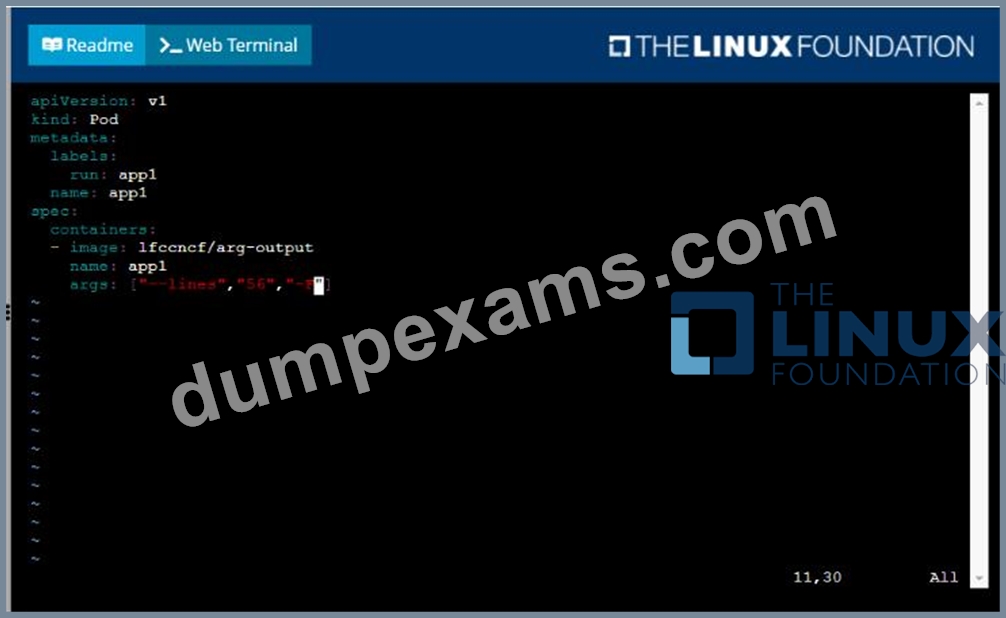
- B. Solution:
Answer: B
NEW QUESTION # 23 
Context
You sometimes need to observe a pod's logs, and write those logs to a file for further analysis.
Task
Please complete the following;
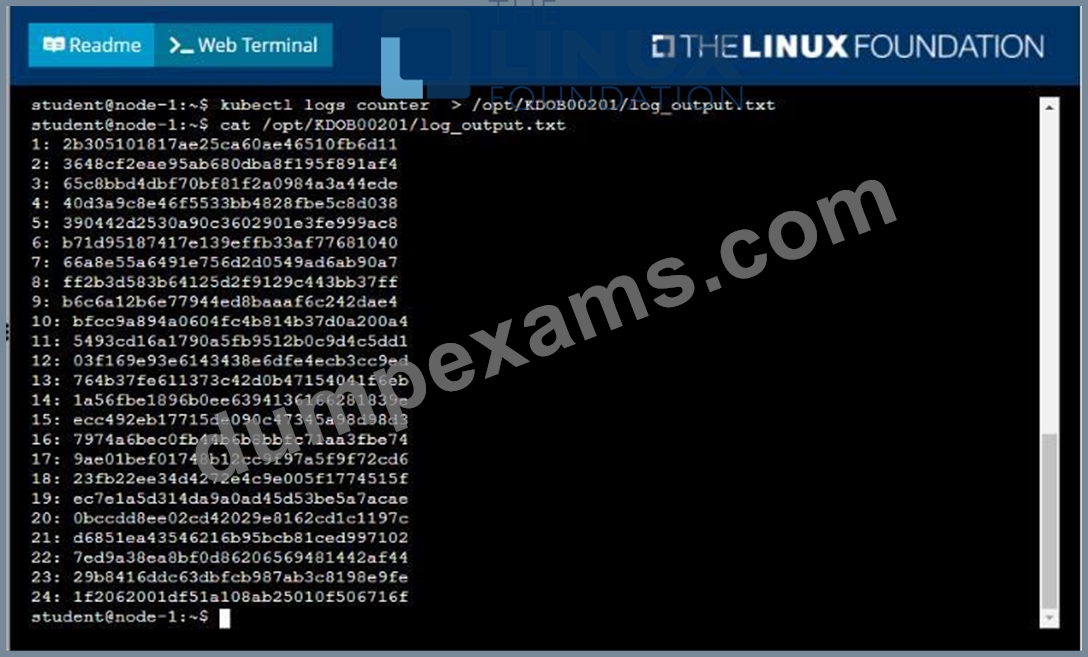
* Deploy the counter pod to the cluster using the provided YAMLspec file at /opt/KDOB00201/counter.yaml
* Retrieve all currently available application logs from the running pod and store them in the file
/opt/KDOB0020l/log_Output.txt, which has already been created
Answer:
Explanation:
See the solution below.
Explanation
Solution: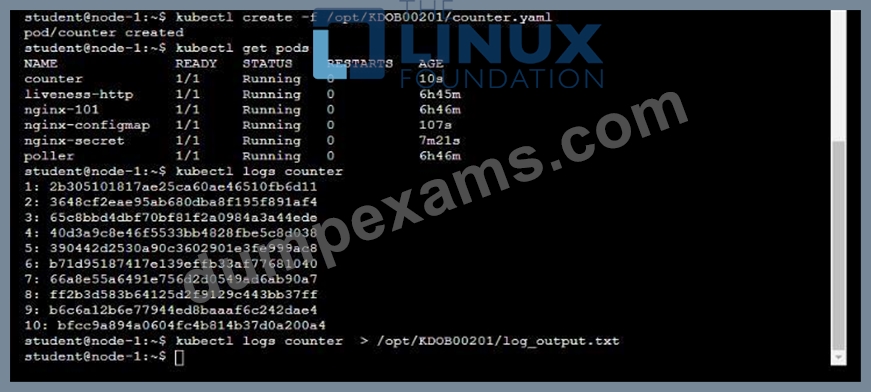

NEW QUESTION # 24 
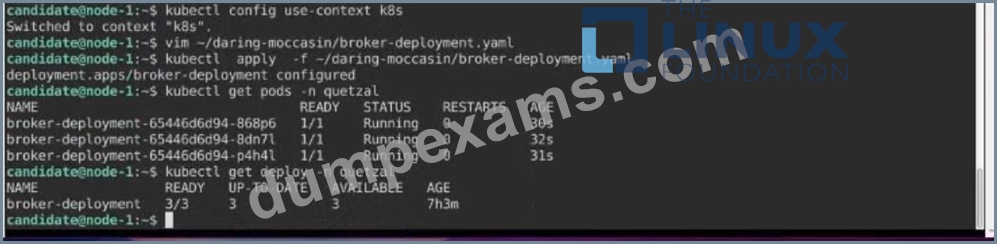
Task:
Modify the existing Deployment named broker-deployment running in namespace quetzal so that its containers.
1) Run with user ID 30000 and
2) Privilege escalation is forbidden
The broker-deployment is manifest file can be found at:
Answer:
Explanation:
See the solution below.
Explanation
Solution:
Text Description automatically generated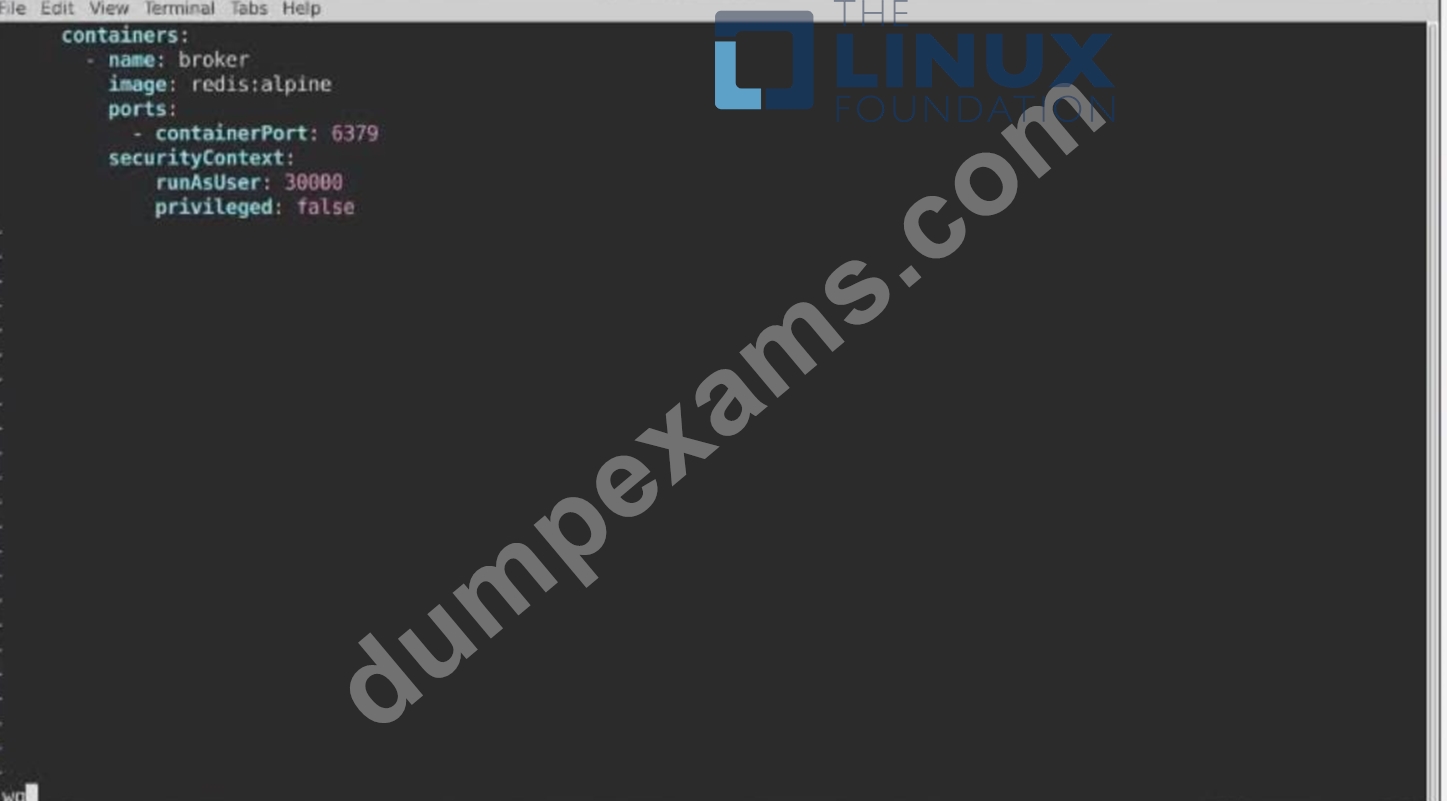
NEW QUESTION # 25
Exhibit: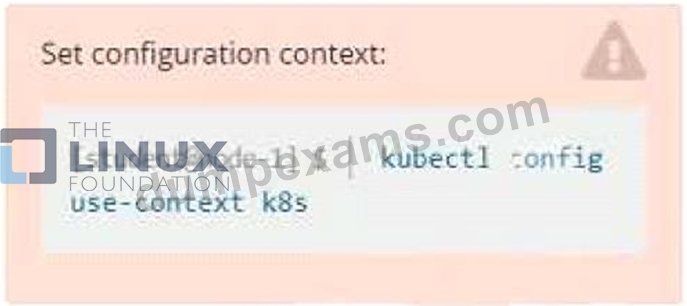
Context
A pod is running on the cluster but it is not responding.
Task
The desired behavior is to have Kubemetes restart the pod when an endpoint returns an HTTP 500 on the /healthz endpoint. The service, probe-pod, should never send traffic to the pod while it is failing. Please complete the following:
* The application has an endpoint, /started, that will indicate if it can accept traffic by returning an HTTP 200. If the endpoint returns an HTTP 500, the application has not yet finished initialization.
* The application has another endpoint /healthz that will indicate if the application is still working as expected by returning an HTTP 200. If the endpoint returns an HTTP 500 the application is no longer responsive.
* Configure the probe-pod pod provided to use these endpoints
* The probes should use port 8080
- A. Solution:
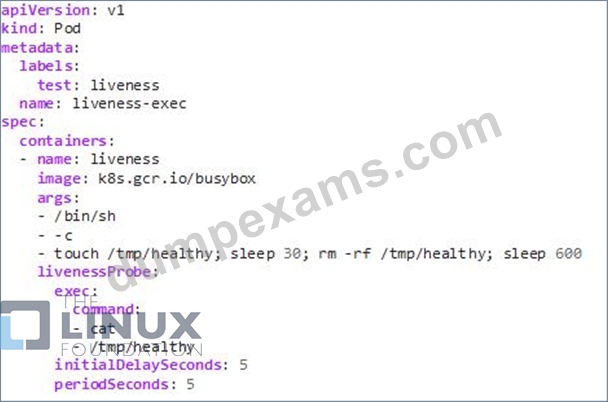
In the configuration file, you can see that the Pod has a single Container. The periodSeconds field specifies that the kubelet should perform a liveness probe every 5 seconds. The initialDelaySeconds field tells the kubelet that it should wait 5 seconds before performing the first probe. To perform a probe, the kubelet executes the command cat /tmp/healthy in the target container. If the command succeeds, it returns 0, and the kubelet considers the container to be alive and healthy. If the command returns a non-zero value, the kubelet kills the container and restarts it.
When the container starts, it executes this command:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
For the first 30 seconds of the container's life, there is a /tmp/healthy file. So during the first 30 seconds, the command cat /tmp/healthy returns a success code. After 30 seconds, cat /tmp/healthy returns a failure code.
Create the Pod:
kubectl apply -f https://k8s.io/examples/pods/probe/exec-liveness.yaml
Within 30 seconds, view the Pod events:
kubectl describe pod liveness-exec
The output indicates that no liveness probes have failed yet:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
After 35 seconds, view the Pod events again:
kubectl describe pod liveness-exec
At the bottom of the output, there are messages indicating that the liveness probes have failed, and the containers have been killed and recreated.
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "k8s.gcr.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Wait another 30 seconds, and verify that the container has been restarted:
kubectl get pod liveness-exec
The output shows that RESTARTS has been incremented:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m - B. Solution:
In the configuration file, you can see that the Pod has a single Container. The periodSeconds field specifies that the kubelet should perform a liveness probe every 5 seconds. The initialDelaySeconds field tells the kubelet that it should wait 5 seconds before performing the first probe. To perform a probe, the kubelet executes the command cat /tmp/healthy in the target container. If the command succeeds, it returns 0, and the kubelet considers the container to be alive and healthy. If the command returns a non-zero value, the kubelet kills the container and restarts it.
When the container starts, it executes this command:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
For the first 30 seconds of the container's life, there is a /tmp/healthy file. So during the first 30 seconds, the command cat /tmp/healthy returns a success code. After 30 seconds, cat /tmp/healthy returns a failure code.
Create the Pod:
kubectl apply -f https://k8s.io/examples/pods/probe/exec-liveness.yaml
Within 30 seconds, view the Pod events:
kubectl describe pod liveness-exec
The output indicates that no liveness probes have failed yet:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
After 35 seconds, view the Pod events again:
kubectl describe pod liveness-exec
At the bottom of the output, there are messages indicating that the liveness probes have failed, and the containers have been killed and recreated.
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory
Wait another 30 seconds, and verify that the container has been restarted:
kubectl get pod liveness-exec
The output shows that RESTARTS has been incremented:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
Answer: A
NEW QUESTION # 26
Exhibit:
Context
A project that you are working on has a requirement for persistent data to be available.
Task
To facilitate this, perform the following tasks:
* Create a file on node sk8s-node-0 at /opt/KDSP00101/data/index.html with the content Acct=Finance
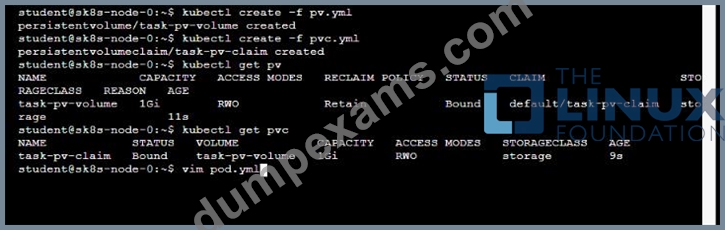
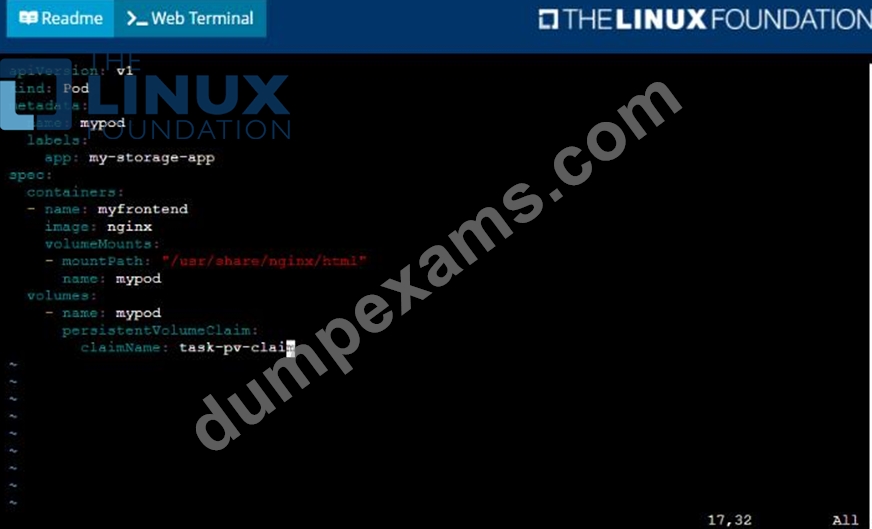
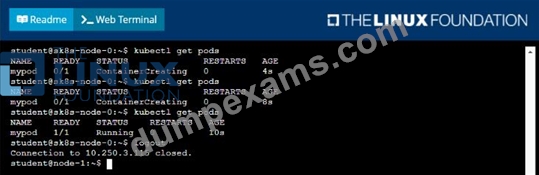
* Create a PersistentVolume named task-pv-volume using hostPath and allocate 1Gi to it, specifying that the volume is at /opt/KDSP00101/data on the cluster's node. The configuration should specify the access mode of ReadWriteOnce . It should define the StorageClass name exam for the PersistentVolume , which will be used to bind PersistentVolumeClaim requests to this PersistenetVolume.
* Create a PefsissentVolumeClaim named task-pv-claim that requests a volume of at least 100Mi and specifies an access mode of ReadWriteOnce
* Create a pod that uses the PersistentVolmeClaim as a volume with a label app: my-storage-app mounting the resulting volume to a mountPath /usr/share/nginx/html inside the pod
- A. Solution:






- B. Solution:
Answer: A
NEW QUESTION # 27
Exhibit: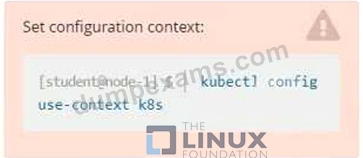
Context
Your application's namespace requires a specific service account to be used.
Task
Update the app-a deployment in the production namespace to run as the restrictedservice service account. The service account has already been created.
- A. Solution:
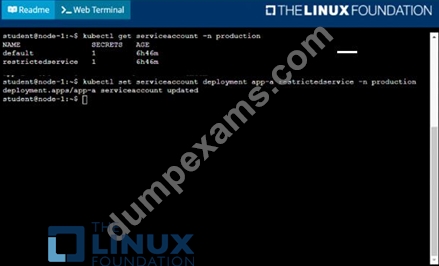
- B. Solution:
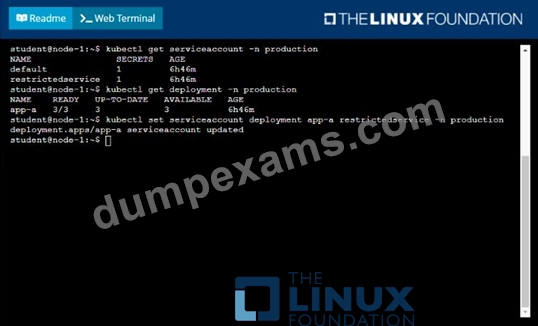
Answer: B
NEW QUESTION # 28
Exhibit: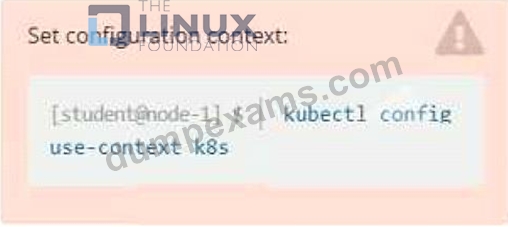
Context
It is always useful to look at the resources your applications are consuming in a cluster.
Task
* From the pods running in namespace cpu-stress , write the name only of the pod that is consuming the most CPU to file /opt/KDOBG030l/pod.txt, which has already been created.
- A. Solution:

- B. Solution:

Answer: A
NEW QUESTION # 29
Exhibit:
Context
Developers occasionally need to submit pods that run periodically.
Task
Follow the steps below to create a pod that will start at a predetermined time and]which runs to completion only once each time it is started:
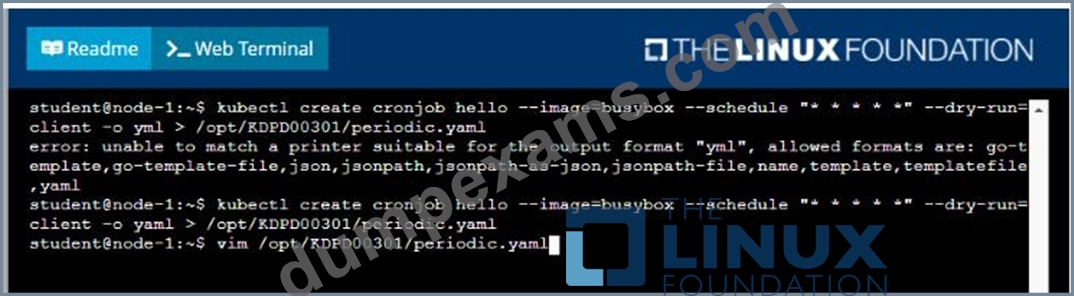
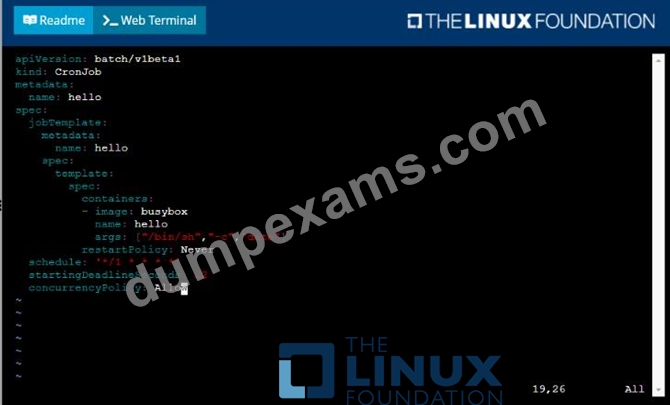
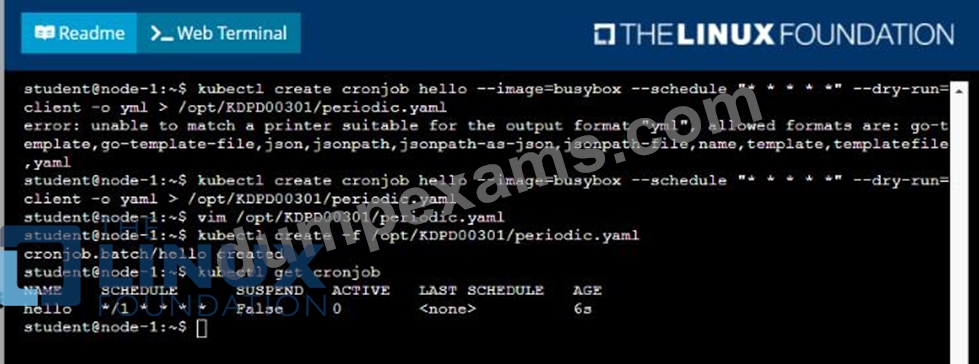
* Create a YAML formatted Kubernetes manifest /opt/KDPD00301/periodic.yaml that runs the following shell command: date in a single busybox container. The command should run every minute and must complete within 22 seconds or be terminated oy Kubernetes. The Cronjob namp and container name should both be hello
* Create the resource in the above manifest and verify that the job executes successfully at least once
- A. Solution:
- B. Solution:
Answer: A
NEW QUESTION # 30
Context
Context
A pod is running on the cluster but it is not responding.
Task
The desired behavior is to have Kubemetes restart the pod when an endpoint returns an HTTP 500 on the /healthz endpoint. The service, probe-pod, should never send traffic to the pod while it is failing. Please complete the following:
* The application has an endpoint, /started, that will indicate if it can accept traffic by returning an HTTP 200. If the endpoint returns an HTTP 500, the application has not yet finished initialization.
* The application has another endpoint /healthz that will indicate if the application is still working as expected by returning an HTTP 200. If the endpoint returns an HTTP 500 the application is no longer responsive.
* Configure the probe-pod pod provided to use these endpoints
* The probes should use port 8080
Answer:
Explanation:
Solution:
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
In the configuration file, you can see that the Pod has a single Container. The periodSeconds field specifies that the kubelet should perform a liveness probe every 5 seconds. The initialDelaySeconds field tells the kubelet that it should wait 5 seconds before performing the first probe. To perform a probe, the kubelet executes the command cat /tmp/healthy in the target container. If the command succeeds, it returns 0, and the kubelet considers the container to be alive and healthy. If the command returns a non-zero value, the kubelet kills the container and restarts it.
When the container starts, it executes this command:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600" For the first 30 seconds of the container's life, there is a /tmp/healthy file. So during the first 30 seconds, the command cat /tmp/healthy returns a success code. After 30 seconds, cat /tmp/healthy returns a failure code.
Create the Pod:
kubectl apply -f https://k8s.io/examples/pods/probe/exec-liveness.yaml
Within 30 seconds, view the Pod events:
kubectl describe pod liveness-exec
The output indicates that no liveness probes have failed yet:
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
24s 24s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "k8s.gcr.io/busybox"
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
23s 23s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e After 35 seconds, view the Pod events again:
kubectl describe pod liveness-exec
At the bottom of the output, there are messages indicating that the liveness probes have failed, and the containers have been killed and recreated.
FirstSeen LastSeen Count From SubobjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
37s 37s 1 {default-scheduler } Normal Scheduled Successfully assigned liveness-exec to worker0
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulling pulling image "k8s.gcr.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Pulled Successfully pulled image "k8s.gcr.io/busybox"
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Created Created container with docker id 86849c15382e; Security:[seccomp=unconfined]
36s 36s 1 {kubelet worker0} spec.containers{liveness} Normal Started Started container with docker id 86849c15382e
2s 2s 1 {kubelet worker0} spec.containers{liveness} Warning Unhealthy Liveness probe failed: cat: can't open '/tmp/healthy': No such file or directory Wait another 30 seconds, and verify that the container has been restarted:
kubectl get pod liveness-exec
The output shows that RESTARTS has been incremented:
NAME READY STATUS RESTARTS AGE
liveness-exec 1/1 Running 1 1m
NEW QUESTION # 31
Exhibit:
Task
You have rolled out a new pod to your infrastructure and now you need to allow it to communicate with the web and storage pods but nothing else. Given the running pod kdsn00201 -newpod edit it to use a network policy that will allow it to send and receive traffic only to and from the web and storage pods.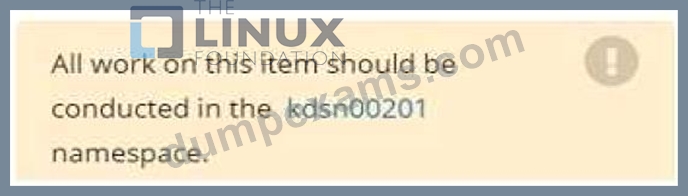

- A. Pending
Answer: A
NEW QUESTION # 32
Task:
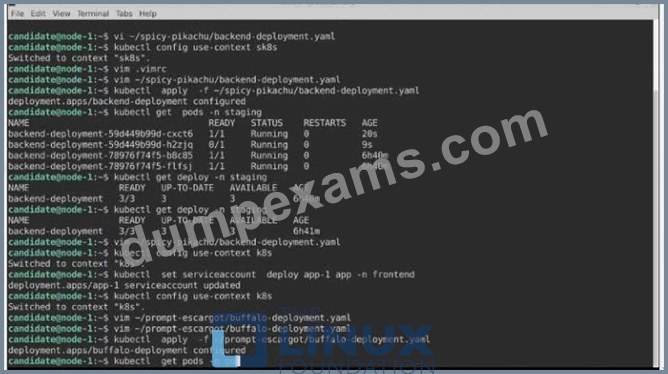
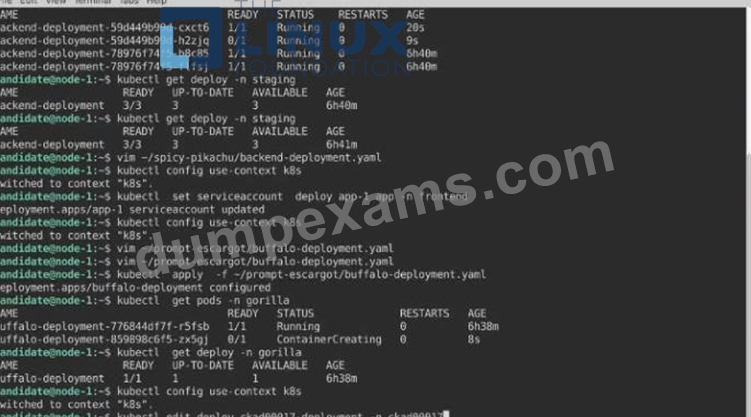
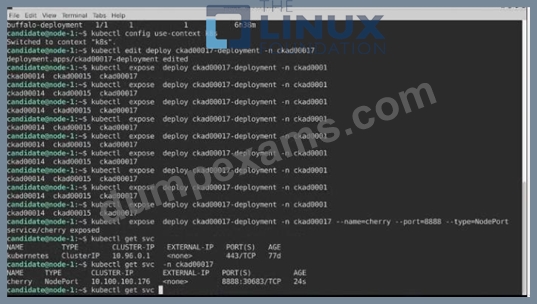
A pod within the Deployment named buffale-deployment and in namespace gorilla is logging errors.
1) Look at the logs identify errors messages.
Find errors, including User "system:serviceaccount:gorilla:default" cannot list resource "deployment" [...] in the namespace "gorilla"
2) Update the Deployment buffalo-deployment to resolve the errors in the logs of the Pod.
The buffalo-deployment 'S manifest can be found at -/prompt/escargot/buffalo-deployment.yaml See the solution below.
Answer:
Explanation:
Explanation
Solution:
Text Description automatically generated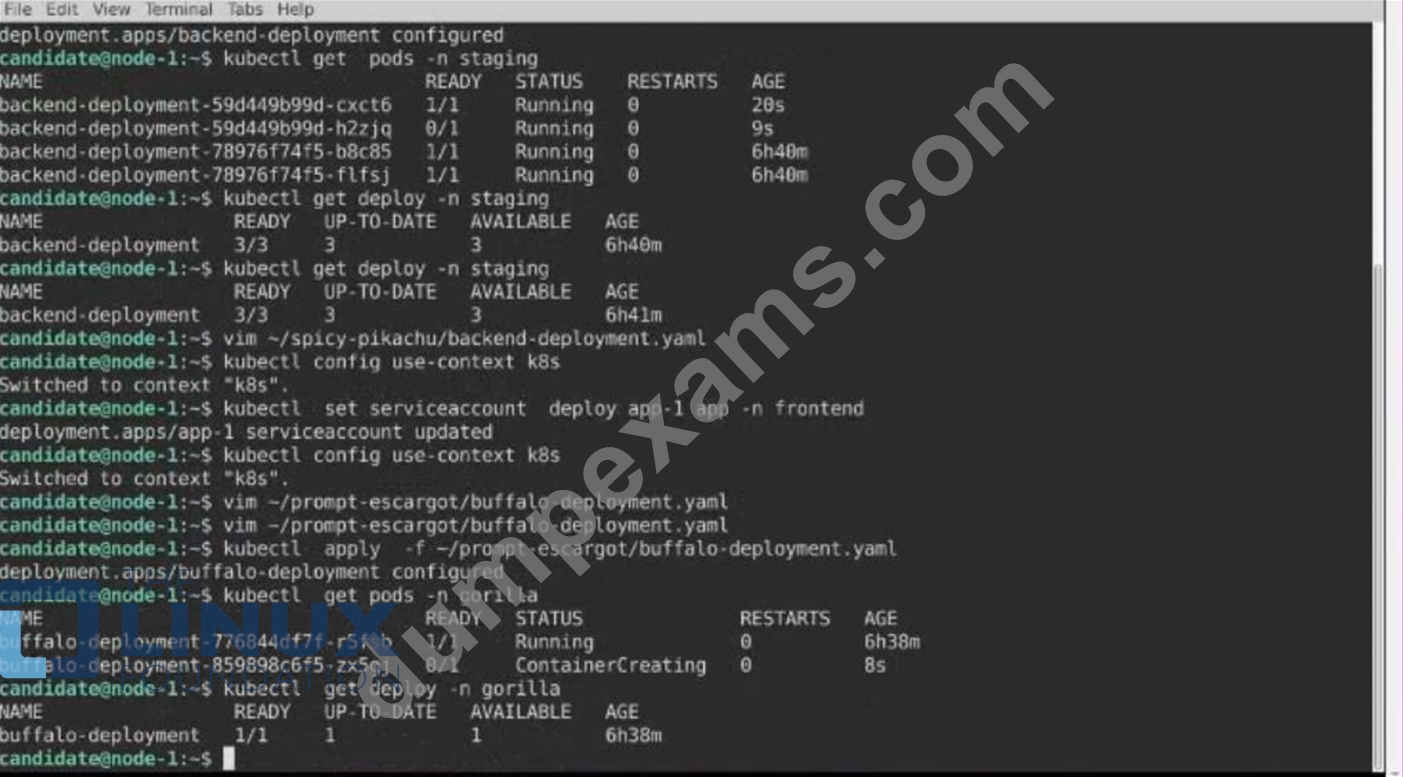
Text Description automatically generated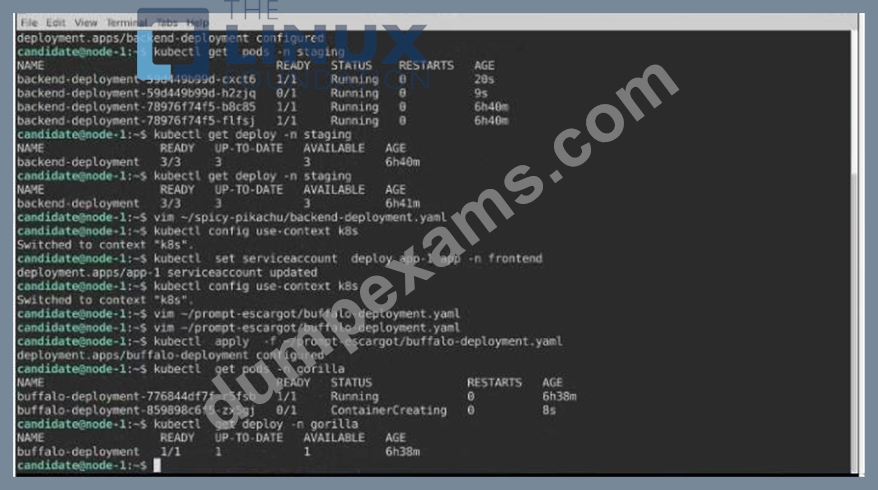
Text Description automatically generated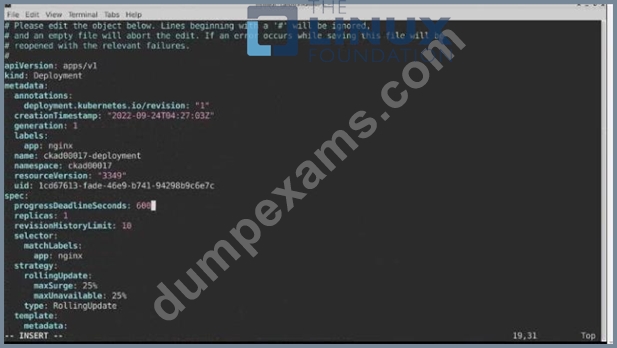
Text Description automatically generated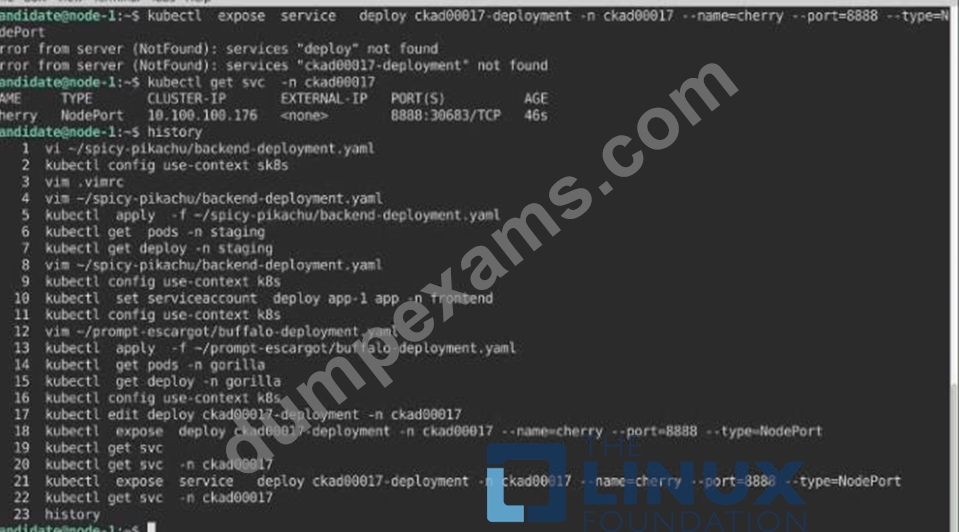
NEW QUESTION # 33
Context
Context
Developers occasionally need to submit pods that run periodically.
Task
Follow the steps below to create a pod that will start at a predetermined time and]which runs to completion only once each time it is started:
* Create a YAML formatted Kubernetes manifest /opt/KDPD00301/periodic.yaml that runs the following shell command: date in a single busybox container. The command should run every minute and must complete within 22 seconds or be terminated oy Kubernetes. The Cronjob namp and container name should both be hello
* Create the resource in the above manifest and verify that the job executes successfully at least once
Answer:
Explanation:
Solution:
NEW QUESTION # 34
Refer to Exhibit.
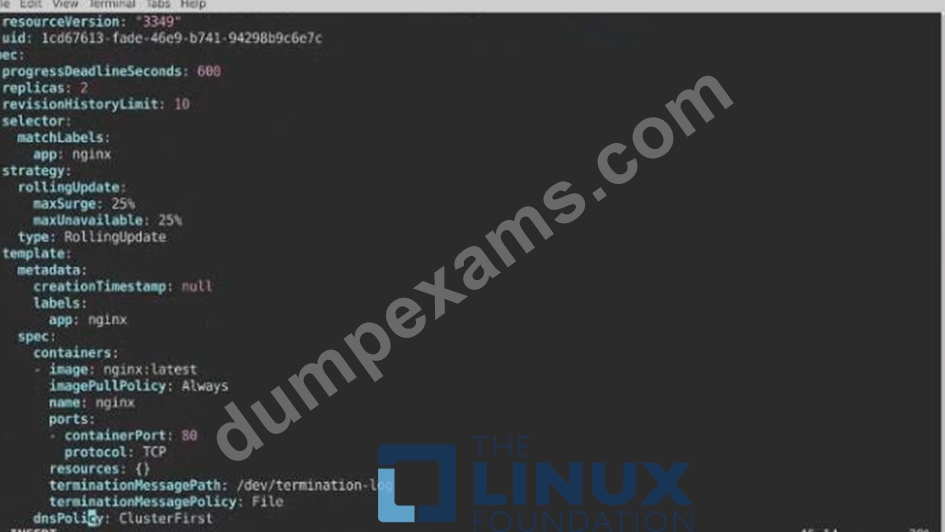
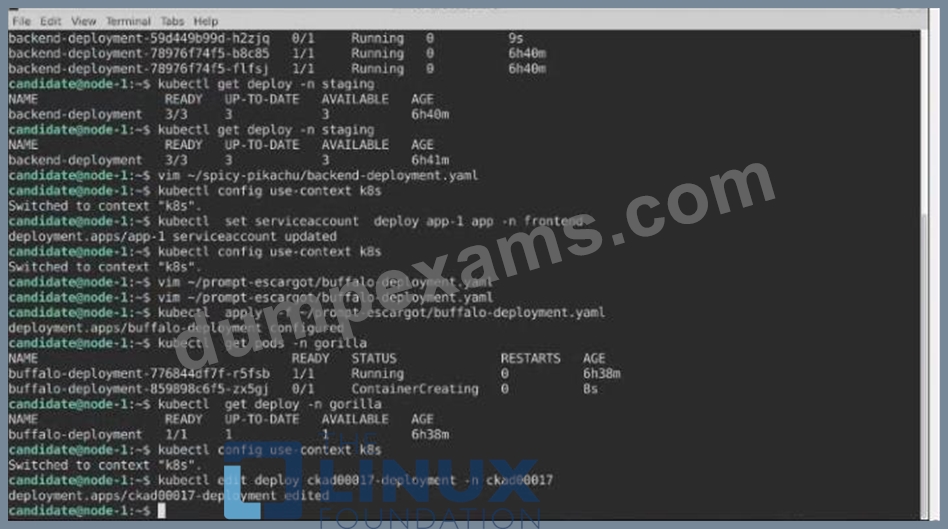
Task:
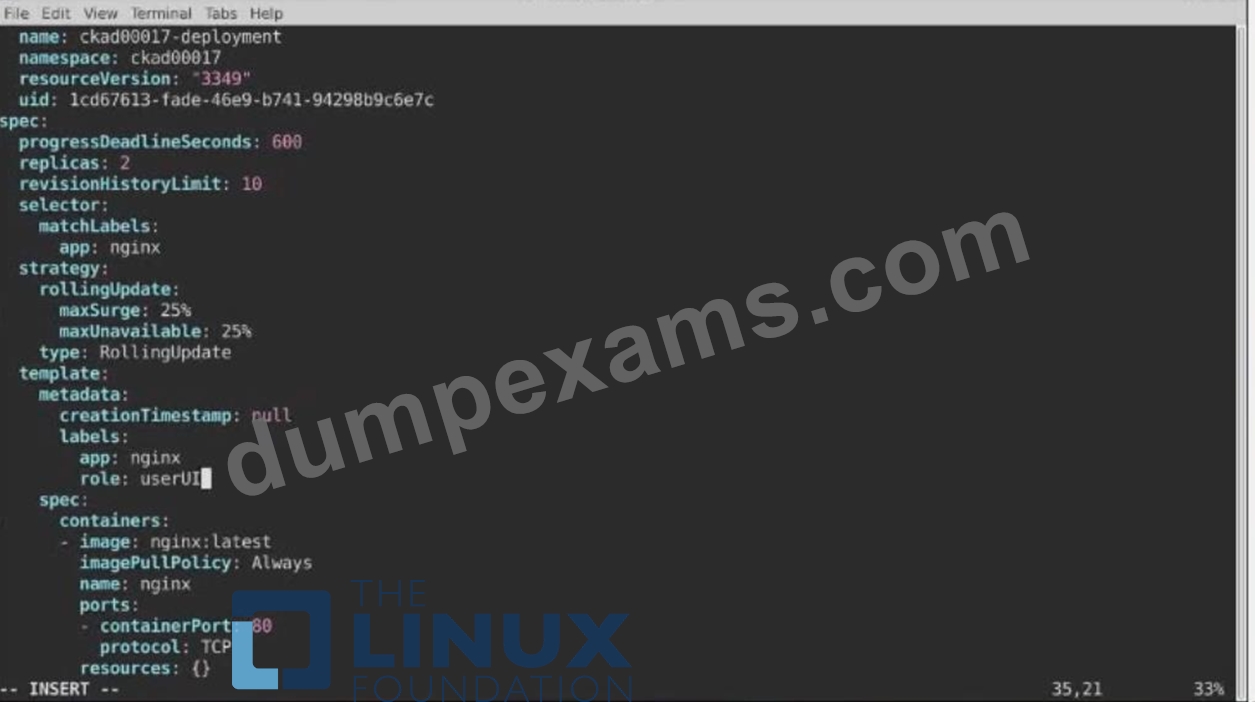
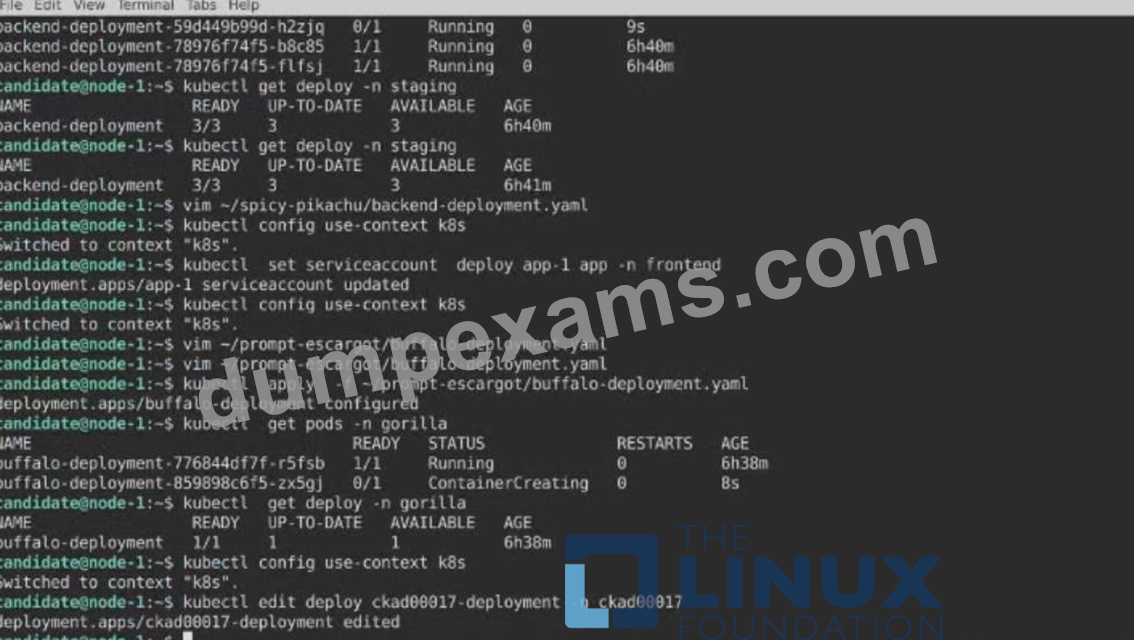
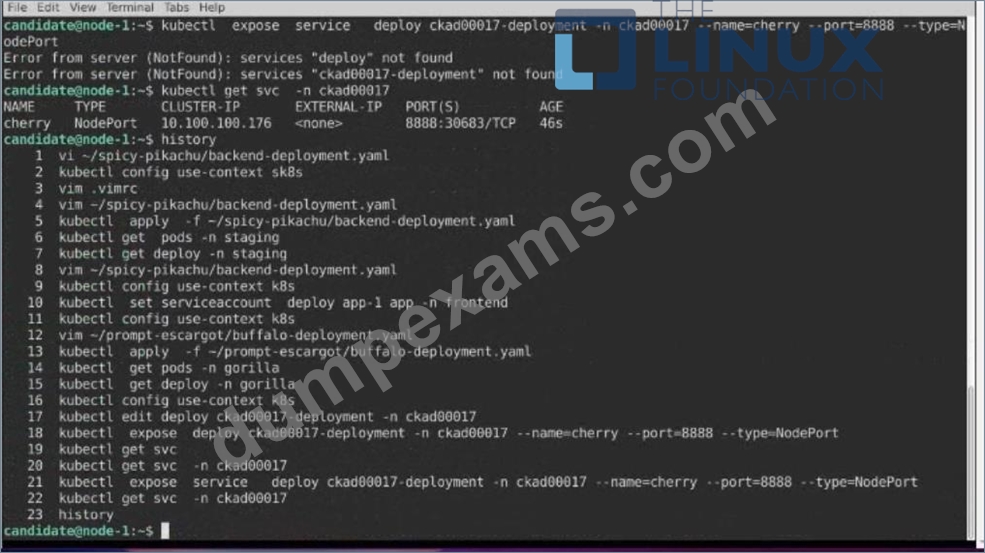
1) First update the Deployment cka00017-deployment in the ckad00017 namespace:
*To run 2 replicas of the pod
*Add the following label on the pod:
Role userUI
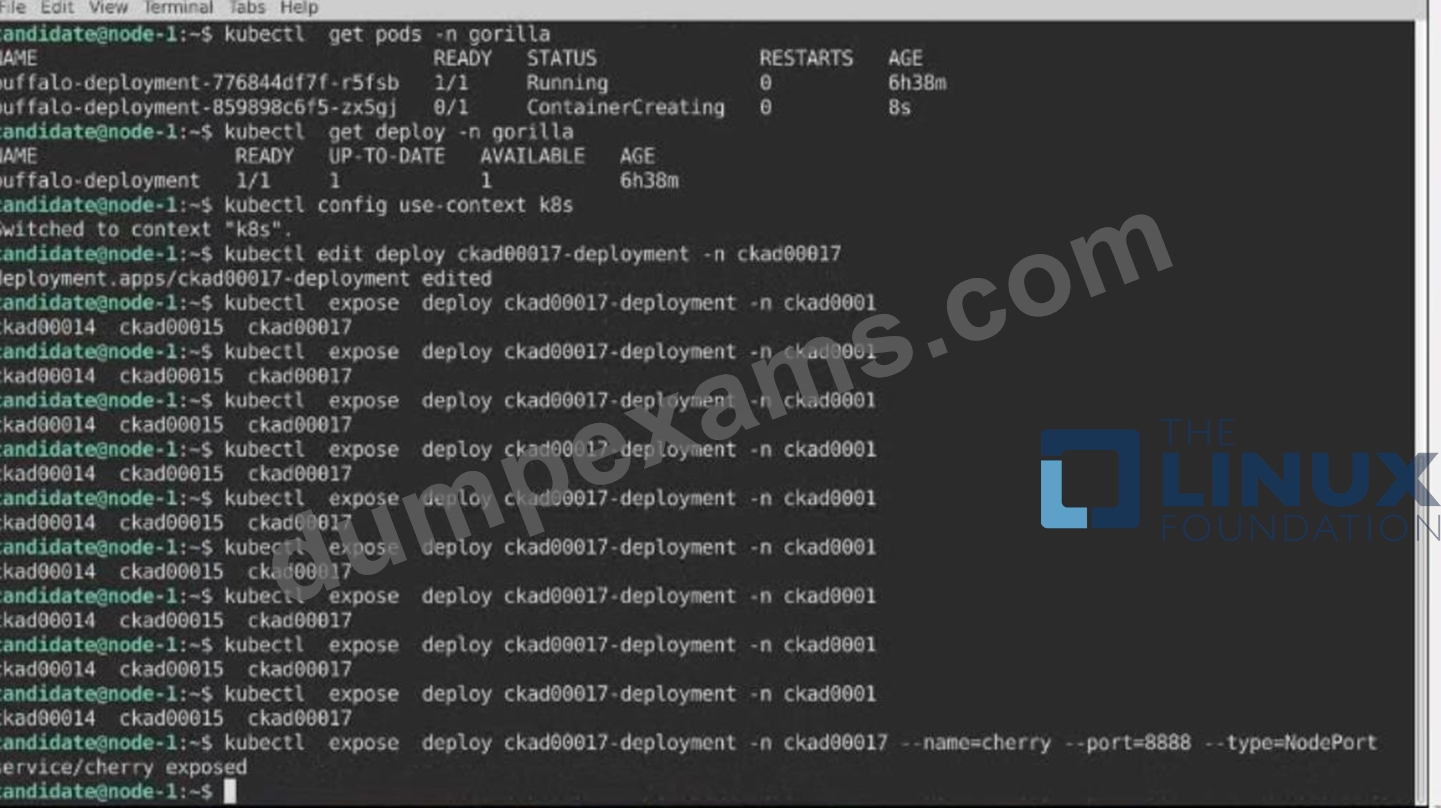
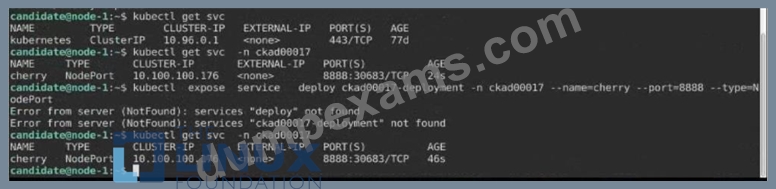
2) Next, Create a NodePort Service named cherry in the ckad00017 nmespace exposing the ckad00017-deployment Deployment on TCP port 8888
Answer:
Explanation:
Solution: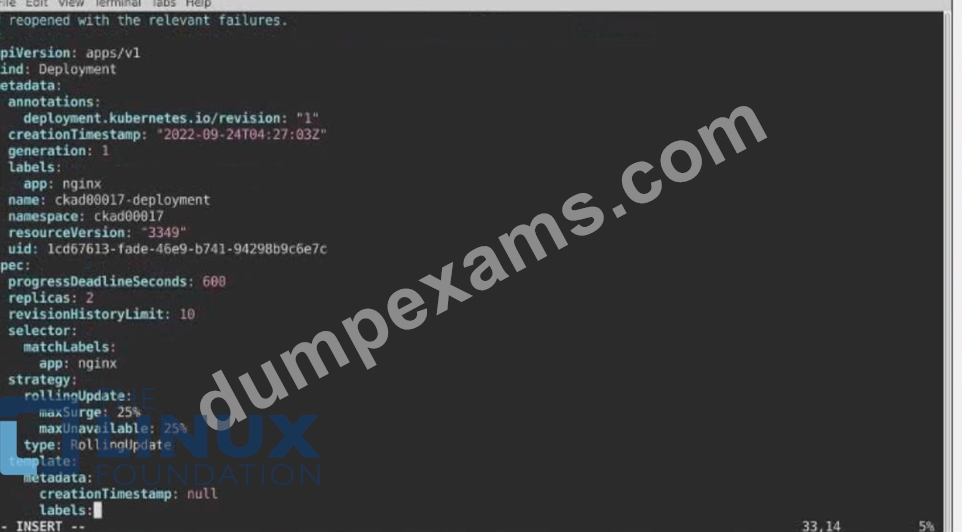
NEW QUESTION # 35
Task:
Create a Deployment named expose in the existing ckad00014 namespace running 6 replicas of a Pod. Specify a single container using the ifccncf/nginx: 1.13.7 image Add an environment variable named NGINX_PORT with the value 8001 to the container then expose port
8001
Answer:
Explanation:
See the solution below.
Explanation
Solution: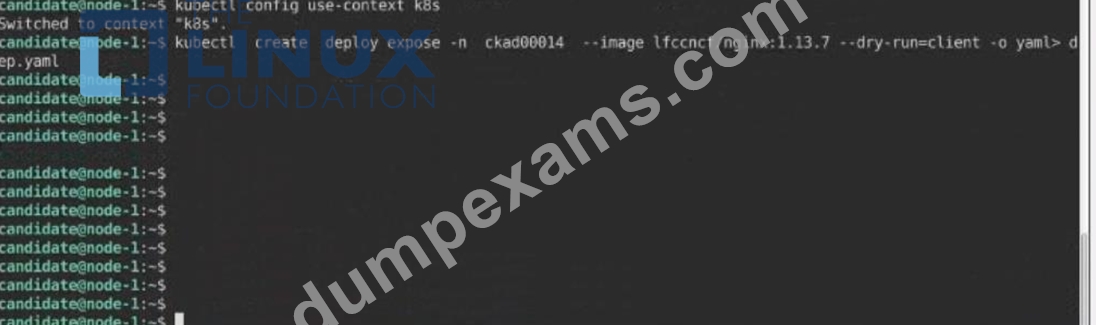
Text Description automatically generated
Text Description automatically generated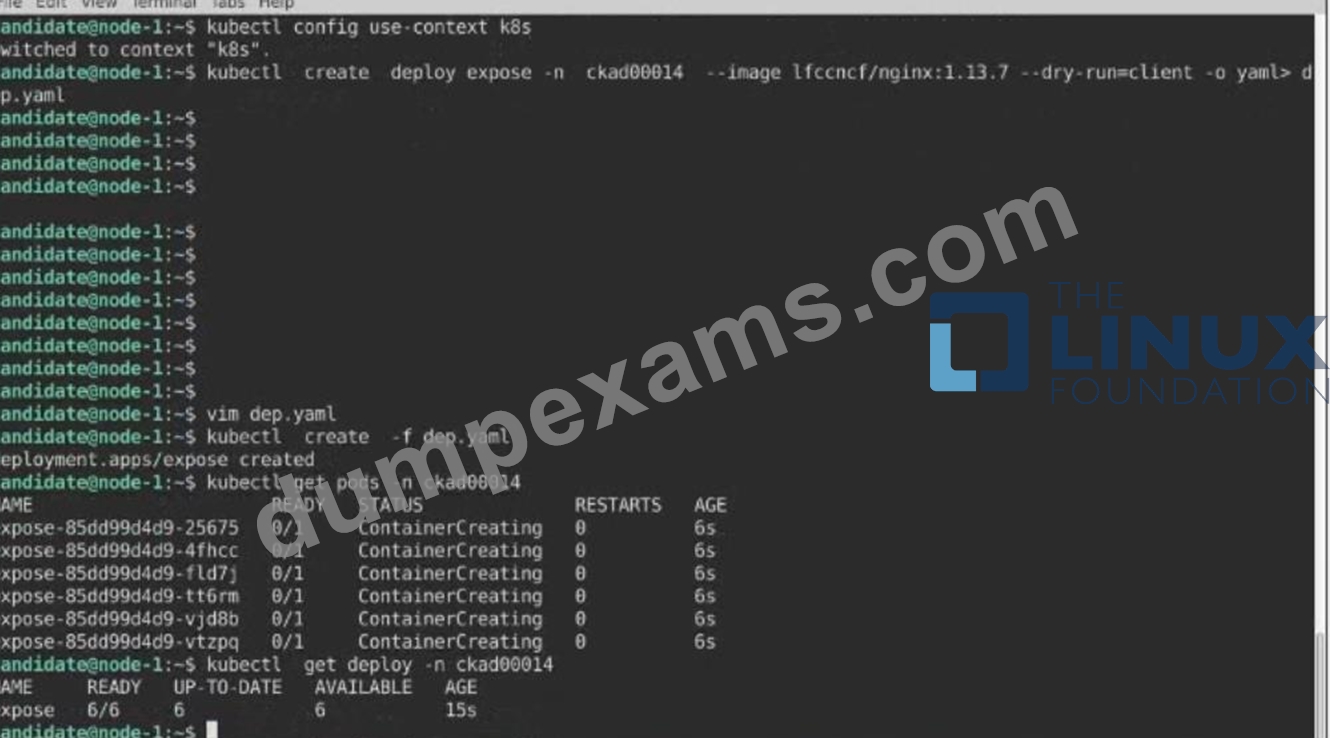
NEW QUESTION # 36 
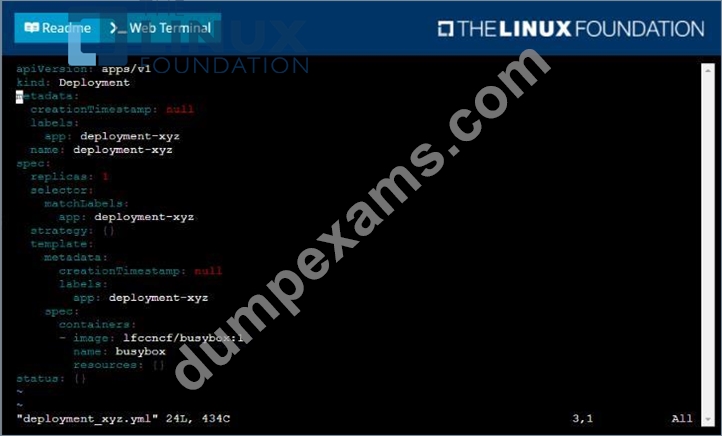
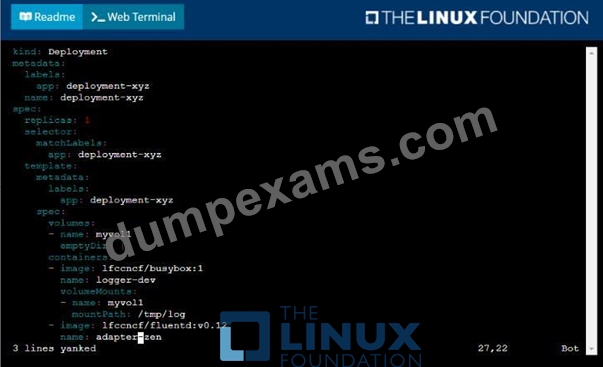
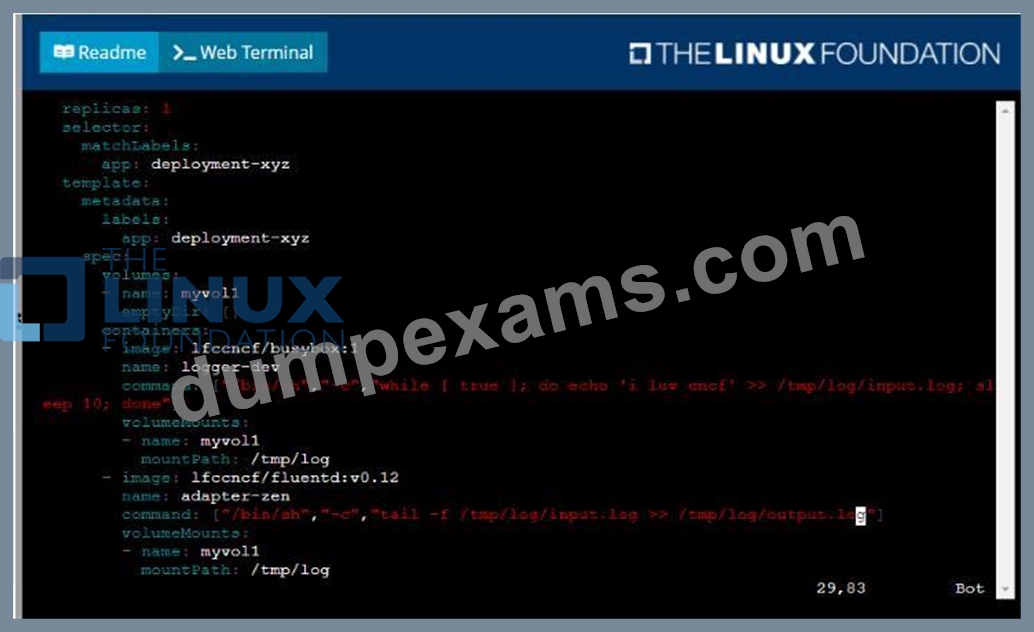
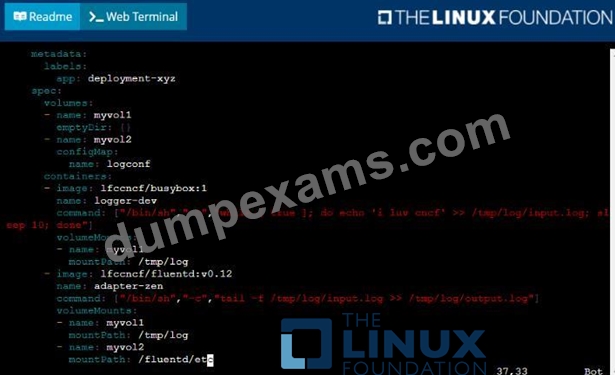
Given a container that writes a log file in format A and a container that converts log files from format A to format B, create a deployment that runs both containers such that the log files from the first container are converted by the second container, emitting logs in format B.
Task:
* Create a deployment named deployment-xyz in the default namespace, that:
*Includes a primary
lfccncf/busybox:1 container, named logger-dev
*includes a sidecar Ifccncf/fluentd:v0.12 container, named adapter-zen
*Mounts a shared volume /tmp/log on both containers, which does not persist when the pod is deleted
*Instructs the logger-dev
container to run the command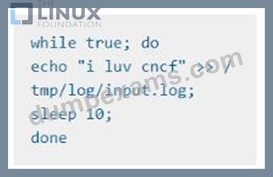
which should output logs to /tmp/log/input.log in plain text format, with example values: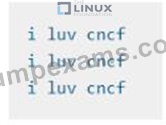
* The adapter-zen sidecar container should read /tmp/log/input.log and output the data to /tmp/log/output.* in Fluentd JSON format. Note that no knowledge of Fluentd is required to complete this task: all you will need to achieve this is to create the ConfigMap from the spec file provided at /opt/KDMC00102/fluentd-configma p.yaml , and mount that ConfigMap to /fluentd/etc in the adapter-zen sidecar container See the solution below.
Answer:
Explanation:
Explanation
Solution:
NEW QUESTION # 37
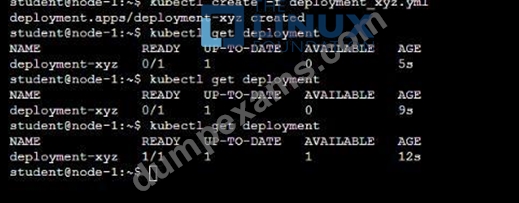
Refer to Exhibit.
Context
It is always useful to look at the resources your applications are consuming in a cluster.
Task
* From the pods running in namespace cpu-stress , write the name only of the pod that is consuming the most CPU to file /opt/KDOBG030l/pod.txt, which has already been created.
Answer:
Explanation:
Solution:
NEW QUESTION # 38
Context
A web application requires a specific version of redis to be used as a cache.
Task
Create a pod with the following characteristics, and leave it running when complete:
* The pod must run in the web namespace.
The namespace has already been created
* The name of the pod should be cache
* Use the Ifccncf/redis image with the 3.2 tag
* Expose port 6379
Answer:
Explanation:
Solution: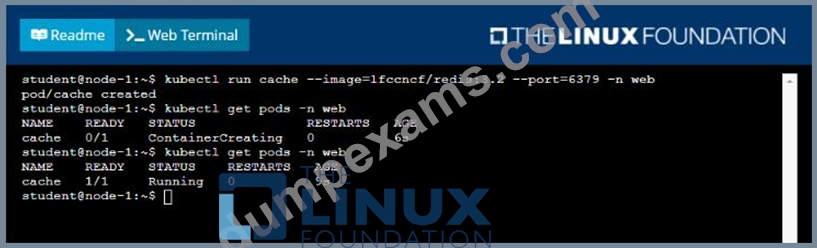
NEW QUESTION # 39
......
Verified Pass CKAD Exam in First Attempt Guaranteed: https://passguide.dumpexams.com/CKAD-vce-torrent.html